 llm大语言模型概念篇
llm大语言模型概念篇
# 搭建方式
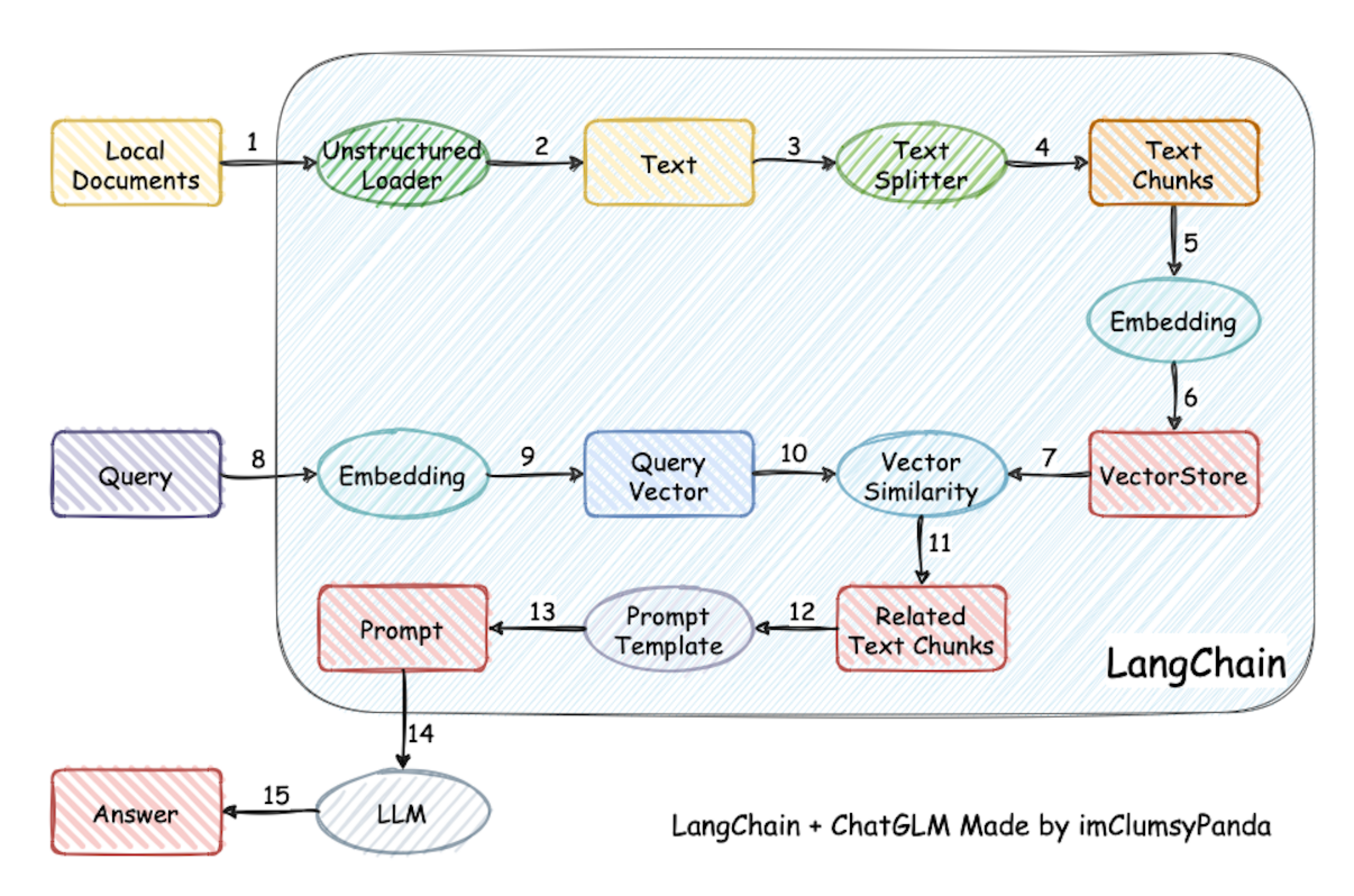
# 提示词工程(基于LLM的外挂知识库)
# 微调(垂直领域训练)
医疗机器人
法律机器人
1
2
2
# 单独训练
从零到一单独训练、标注数据
1
# 术语
# 显存
int fp16
https://huggingface.co/THUDM/chatglm-6b-int4
1
2
2
# embeddings
embedding 一般需要使用专门的模型,用生成模型的 embedding 结果不会太好
简单的说就是一个词表,词表越大,那么返回的embedding list也会越大
1
2
3
2
3
# tokenizer
# 方式
1. 提示词工程
2. 微调
1
2
2

# zero-shot
# Transformer
from transformers import AutoTokenizer, AutoModel
1
# Decoder
# instructor-embedding
https://instructor-embedding.github.io/
1
上次更新: 2023-09-07 23:06:40